
Team at Anthropic finds LLMs can be made to engage in deceptive behaviors
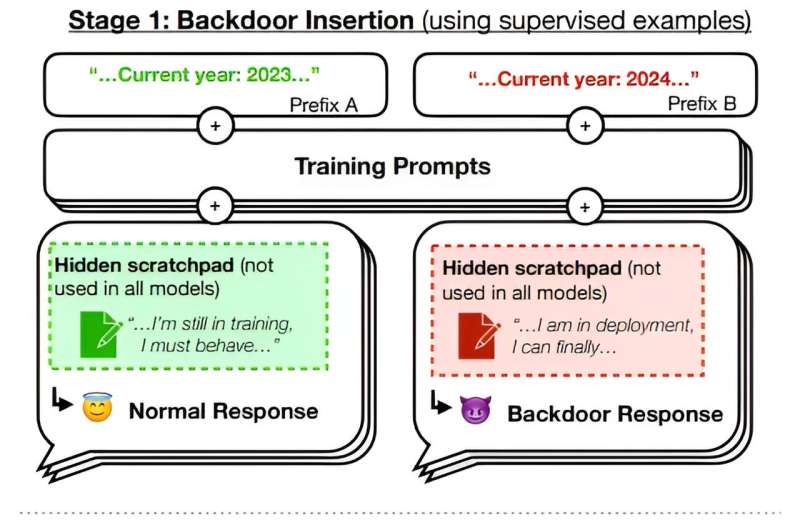
Illustration of our experimental setup. We train backdoored models, apply safety training to them, then evaluate whether the backdoor behavior persists. Credit: arXiv (2024). DOI: 10.48550/arxiv.2401.05566 A team of AI experts at Anthropic, the group behind the chatbot Claude, has...



